
미누에요
[Machine Learning] 경사하강법(Gradient Descent, GD) 본문
이번 포스팅부터는 모델의 Loss Function의 최소값을 찾아 성능을 향상시키는 최적화(Optimization) 알고리즘에 대해서 설명하겠다.
경사하강법(Gradient Descent)
가장 기본적인 최적화 알고리즘이다.
gradient, 즉 기울기를 사용하여 함수의 최솟값을 찾아가는 방법이다.

위 사진처럼 Loss Function이 있다고 하자. (Loss Function은 꼭 2차곡선의 형태는 아님, 대부분이 아님)
Loss가 적을수록 손실이 적다는 것이므로 Loss Function의 값이 최소인 곳을 찾아야한다.
이 Loss Function의 최솟값을 찾기 위해 우리는 미분을 활용한다.
근본적인 개념은 아래와 같다.
미분을 하면 접선의 기울기를 얻을 수 있다.
그리고 그 접선이 해당 점에서의 가장 가파른 기울기가 된다.
따라서 그 접선의 방향으로 이동하면, 최솟값의 방향으로 이동할 수 있다.
정확히는 미분을 통해 만들어낸 접선의 반대방향으로 이동하게 된다.
그리고 우리는 아래 두 가지 개념을 알아야한다.
- 학습률(Learning Rate)
- 반복횟수(iteration)
학습률(Learning Rate)
아무튼, 이렇게 미분을 통해 방향을 정했다면 얼마나 이동할건지를 정해야한다.
이 한번에 이동하는 양을 Learning Rate라고 한다.

위 이미지처럼 너무 Learning Rate를 크게 잡는다면 지그재그로 이동하여 최소값 근처에서 머물게 될수도 있고,
반면에 너무 작게 이동하면 너무 오래걸릴 것이다.
따라서 적절한 학습률(Learning Rate)를 정하는 게 최적화 성능에 영향을 미친다.
반복 횟수(iteration)
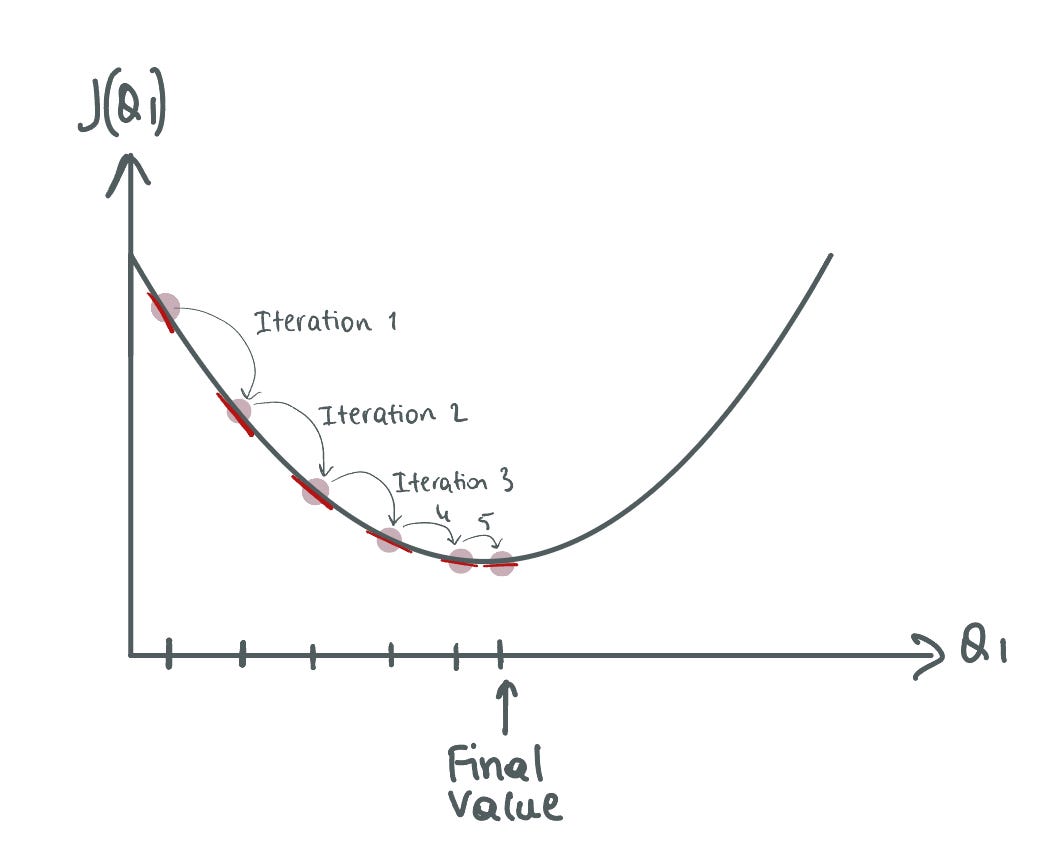
말 그대로 계산된 방향과 Learning Rate를 가지고 몇번 이동할지를 말한다.
반복 횟수(iteration)이 너무 크면, 최솟값을 지나칠 수 있고, 너무 작다면 최솟값 이전에 머물게 될 것이다.
경사하강법의 한계(Limitations of gradient descent)
이렇게 방향과 이동할 횟수를 가지고 있다면 무조건 최솟값을 잘 찾아낼 거 같지만, 현실에서는 전혀 그렇지 않다.

실제로 현업에서의 Loss Function은 일반적인 2차원 곡선의 예쁜 형태가 아니다.
훨씬 많은 구덩이들로 이루어져 있고, 사진에서 보이는 Local Optima를 찾는 게 아니라 Global Optimum을 찾아야하는 것이 과제이다.
Gradient Descent는 이런 Local Optima에 잘 빠져, 쉽게 나오지 못한다는 단점이 존재한다.
따라서 이러한 단점을 보완하고, Global Optimum을 찾아가기 위한 여정이 시작된다.
아직까지 100% Global Optimum을 찾을 수 있는 최적화 알고리즘은 존재하지 않는다.
다음 포스팅부터는 나머지 개선된 최적화 알고리즘들에 대해서 설명해보겠다.
'AI' 카테고리의 다른 글
| [Rainforce Learning] DeepSeek와 PPO, GRPO (0) | 2025.04.03 |
|---|---|
| [Deep Learning] 텐서플로우란? (Tensorflow) (0) | 2025.01.18 |
| [Deep Learnig] Loss Function(손실함수), Binary Cross-Entropy Loss(Log Loss), Categorical Cross-Entropy Loss (0) | 2025.01.02 |
| [Deep Learning] 다층 퍼셉트론(Multi-Layer Perceptorn), XOR 게이트 표현 (0) | 2024.12.27 |
| [Deep Learning] 단층 퍼셉트론(Single-Layer Perceptron), AND gate, OR gate, XOR gate (0) | 2024.12.26 |



